


Dunning-Kruger Illustrated, ASMR Explained & Bad Non-Official Czech Data
Another of these statisticians' spats that we all love

Context
A few days ago, Steve Kirsch returned & initiated a new mess1, with analytics on the Czech Republic, derived from a bad university-produced record-level dataset2, compiled by Univerzita Palackého v Olomouci. The result is, as usual, representing the unvaccinated dying more than the vaccinated, based on awfully confounded data.
(to whom the credit of a good part of the interesting findings developed here is due) & myself analyzed this data & decided to postpone our current 8 pages of data consistency analytics & subsequent demonstrations, while waiting for the publication of the official CZ dataset - announced soon to come by UZIS, their statistical office. Shortly explained (we will briefly expand on that below), the current dataset is riddled with flaws & unknown confounders, and shouldn’t be used to draw conclusions - but merely to demonstrate how poor the observational data used is, in general.In the following developments and controversies, Henjin (ex Mongol_fi), 8-bits data mixer masquerading as “experienced conspiracy theorist”, produced yet another of these Chat-GPT analytic flows3 that he masters like no one else, in his urge to demonstrate that the jabs are working as intended.
The character appeared on the Twitter-scene end 2023, and his only endorsed conspiracy to date is “all Jews are bad”. Don’t ask him to justify this view, or that makes you a “baby truther” only worthy of his despise.
In the course of our own analytics, I realized with surprise, painfully re-reading his non-commented and non-indented code, that what he called "ASMR"4 (Age Standardized Mortality Rate) was using a flawed rating system, not a true age-standardized rate as it should be. ASMR involves taking a population with a known mortality rate in each 5-year age band, which gives a crude mortality rate for the whole population. You then recalculate the overall mortality rate, assuming those same age bands maintain their mortality rate, but you use the population distribution from the "standard" population to recalculate the overall mortality of your population. It is a specific method to control for different age distributions among populations or over time, which, by definition, involves the use of a "standardized" population. Yet, at this time, the page explained that the following was an ASMR without any reference population being loaded, which was rather surprising.

Without noting that the “way he figured out” was a bastardized version of my latest analytics on New-Zealand5, I kindly pointed out this ASMR terminology issue to him on July 196. Running the code on his archived page resulted in the following plot. Said plot was taken at face value by various analysts, and generated further virtual ink which could have been spared.

While one could have expected a public acknowledgement of his error without further delay, that’s… not what happened, and Henjin went for editing page & code7, of course without erratum. But at least we gained more colors.
Judging useless to reply to this error pointed out, he reappeared yesterday in another thread, for his 40th~ attempt to have me doubting Jikkyleaks. At which stage, annoyed, I stressed again the issue8.
Followed a long digression where neither papers explaining ASMR9 or ChatGPT definitions (according to his stated preference10) succeeded in having him admitting his mistake. His argument is “I use a non-standard standard population. It's still ASMR and the same formula”11.
Hence the current break-down.
Henjin’s thing detailed
So…
keeping only his “Unvaccinated” and “All Vaccinated” categories,
shortening his code for sobriety,
commenting it for readability,
and truncating to the relevant period,
without altering a line of its behavior,
… this is what Henjin is currently calculating (R12):

Using a file he extrapolated13 from the Kirsch-provided dataset, he picks what he pre-calculated (poorly) to be “alive” and “dead” populations for each dose, at each date14.
From a second file provided by the CZ institute15, he picks his reference population - being the 2021 CZ data.
He then employs various hacks & smoothing to make the gum stick and produce the end chart he calls “ASMR” - the daily deaths rates in each age groups, weighted against the people of age, still alive, according to his “random birth dates estimates”, being barbarically weighted against the CZ 2021 population deemed “standard”.
Calculating ASMR from bad data
To calculate (basic) ASMR in order to produce what Henjin attempted, one requires 2 source files:
A similar file to Henjin’s one regarding the population available, for each age & dose received. As stated on point 1 of the previous section, I disagree with the method used to generate this file originally, but given it’s just about demonstrating the difference in calculation on a crappy metric, let’s stick with it for now to simply compare the end result.
A (real) standardized population, which is a fiction existing nowhere but in statistics16. It doesn’t matter much which commonly acknowledged standard you use, being the WHO one (default, which replaced the US standard17 in 200018) or the EU one19 (common - as long as you precise it - currently on its 2013 revision20 of the Waterhouse et al., 1976 standard). Here, we will use the WHO one, which contains percentages by 5-year age groups, summarized in the following .CSV file21.
From here, this is what the chart should have looked like, to be titled ASMR without misleading the readers (Perl22, R23).

From which data does such dataset originate
At this stage, it is useful to understand how such dataset is created, at state level. Most - if not every modern country - will have a well maintained & robust Civil Registry database - containing their population, kept by the Interior Ministry, or is delegated to the country’s statistical office.
Most - if not every modern country - will have initiated a distinct database from this Civil Registry to store vaccinations data. Some (rare) will have had, when COVID started, an existing infrastructure compliant with 1 to N doses of vaccines administered to each citizen. Most will have improvised their tools, and evolved them as the information evolved (for example, planning originally for 2 doses by citizen, then adjusting later for 4 boosters, then adjusting for up to 10 boosters, etc.)
At each of these decisions and adjustments, opportunities for poor data management, structural errors, and failures in later reconciliations are created.
From these statements which I don’t think anyone understanding data will contest, can be derived two main scenarios :
In an optimal scenario, the country would have a perfect Civil Registry data. This data would contain every useful 1 to 1 data concerning the citizen (date of birth, date of death if any, social security number, current height, current weight, current educational level, etc.).
When people would apply to vaccination, they would simply provide their social security number. Everyone would have a social security number, know it, and prior to administer any vaccine, the doctor, pharmacist or nurse would verify that this social security number exists in the system, cross-confirm the identity of the recipient, and would instantly log the dose in the system after it had been administered - someone else being ready to intervene if the patient had an incident following the injection.
2 years later, the data on first doses administered would perfectly fit the state registries on vaccination administered at individual level.
In the end, knowing how many of the citizens are vaccinated would simply be a matter of using the social security number to match civil registry records & doses records, producing perfect record level data.
→ Needless to say this country exists only in the mind of a few statisticians.
In a less optimal scenario, reality and human errors interfere. Some people provide erroneous social security numbers, or the country simply requires a first name, last name, and date of birth to allow someone to get vaccinated. The agents in charge are capturing the data which people can provide them prior to capture the doses administered, when they have time to proceed with the later. Errors occur when providing social security numbers, entering them, these numbers aren't checked by the system for existence prior to validation, etc. These problems will be naturally inflated in countries with non-standard Latin alphabets, making name matching from one database to another quite hazardous (“Ničolá” in the civil registrar data can be “Nicola” in the “doses data” and for a computer, these aren’t the same thing at all).
To edit metrics, the state statisticians are adjusting their database in a hurry, and creating duplicate data by adding data to the vaccination database which doesn’t belong here - for example, the date of deaths of subjects. NZ, covered in various previous articles, offered an excellent example of such “data duplication” & conflicts.
→ This will be most of the countries presented as “good data”. Of course there is far worse, such “country which vaccinated in stadium with improvised workers, without taking precisely any valid info”. If you’re having doubts CZ was in this case, read the “I’m having problems” section on this page24.
How such dataset is created
Having in mind that most countries will derive from “Scenario 2” above, let’s pick an imaginary country, of 10 inhabitants - 5 vaccinated, and 5 unvaccinated, of whom 2 died in the recent period - for ease of illustration.
This country will maintain the following 2 databases, represented as follows.


In this simple example, 2 entries out of 5, in the vaccination records, have issues :
Eva Černá is named Eva Cerna in the vaccination database, and has a social security number error
Jana Svobodová hasn’t provided a security number at all.
Upon matching these two databases, the operator will therefore have, based on the social security number, 3 out of 5 of his subjects matched.
He will then, looking for the subject on the basis of the name & date of birth, easily find Jana Svobodová. At this stage, he will be left with only one record, non-matched, who died.
He can resolve this conflict one of three ways :
Passing through an advanced reconciliation process - looking for the most likely unvaccinated match in his civil registry using Levenshtein distance, and other tools to analyse potential DOB errors, social security numbers errors, etc.
→ This might sound simple in a database of 10 people but becomes harder in a database of 100.000 people - not to mention several millions, and practically speaking, almost none will do that unless he has a real interest in getting to the truth of the matter.
Deciding that subjects who aren’t found in the Vaccination Database are considered unvaccinated, while keeping the Civil Registry as “reference”. The results will be a 10 subjects database, with 2 unvaccinated deaths - instead of the 1 vaccinated - 1 unvaccinated, which happened in reality.
Deciding to merge these two databases - not to ignore a vaccinated death. The result will be an 11 subjects output, with 2 unvaccinated deaths, and 1 vaccinated death, resulting in more deaths than occurred in reality.
So, why is ASMR a terrible metric ?
First, ASMR, like the Mongol-thing first described, are both integrating infant deaths by default - which will constitute the bulk of almost fully unvaccinated deaths under 12 - weighting on the groups balance.
The CZ census projection for the covered period - here 2022 & 2023 January 1st populations by ages25 - which we will pick on Eurostats26 - is available. The last physical census occurred in 2011, with CZ moving to an online census in 202127.
Mongol had produced a 2021 “record level data to census comparison”28, which we declined, simplifying it to simply check against EuroStat figures only (R29).

From higher percentages in the record level data, he concluded that it may include non-residents - but that give or take 1.5% of the population, we were pretty much fitting.
The problem is that performing the same comparison produces drastically different results at cut-off 2022-12-31, when compared to the January 1st 2023 census data a day later - with all age groups being under Census figures - aside for the 75+ (R30).

It means, obviously, that too many people have been counted as “dead” in the record level dataset for the “active population” - that the record level data is incomplete - or that the census data is terrible - or all of these options together - make your pick.
Lastly, ASMR deprives us of more relevant & granular analytics by age groups, which would make rather obvious that the dataset, as such, is unusable for any analysis of effectiveness.
Miscategorization & data integrity issues - Death Rates in Age groups 10 to 24, in 2021
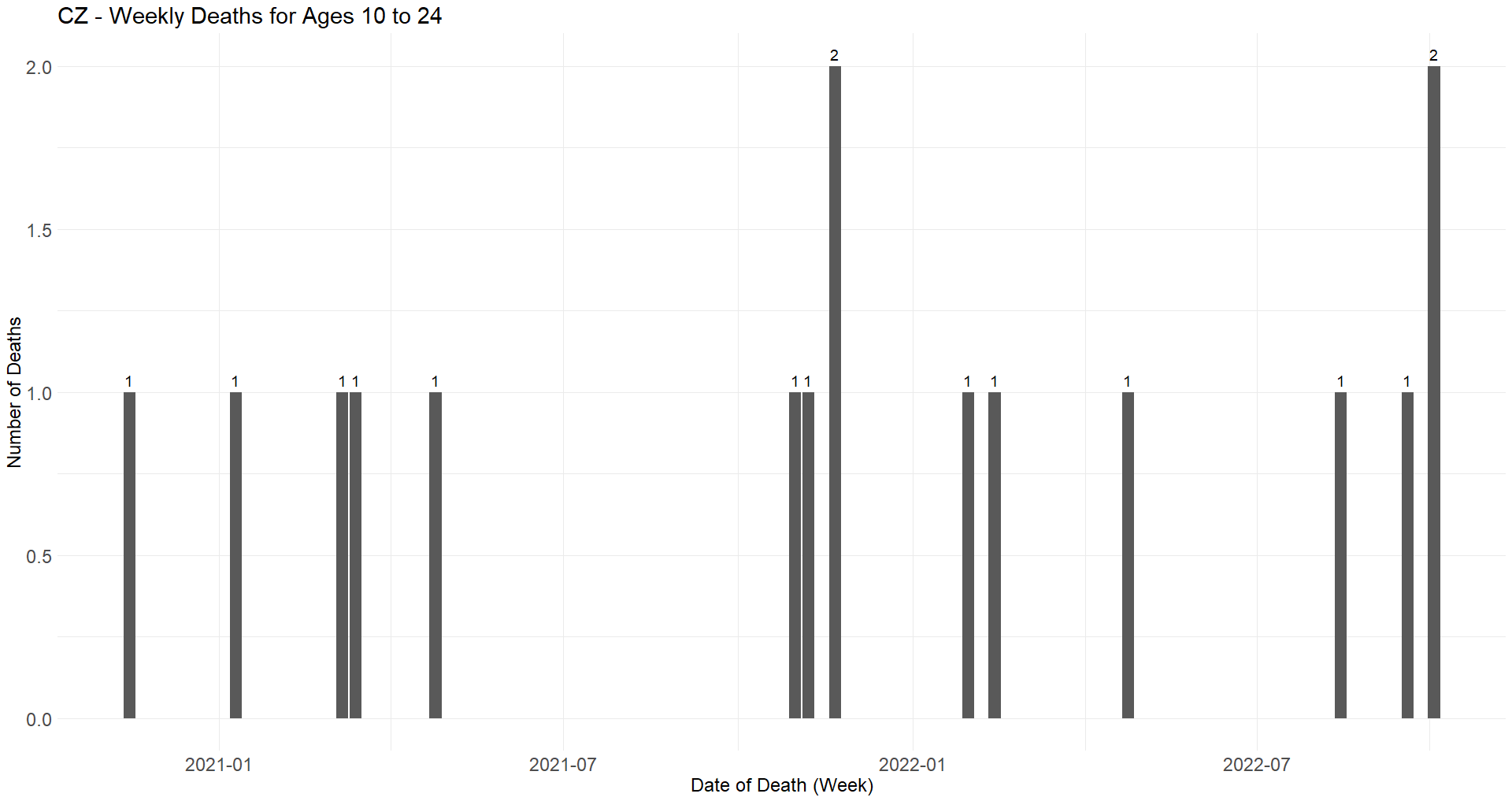
The Czech Republic keeps on its statistical platform a file containing all the COVID deaths registered within the state during the pandemic, with date of death, age, and sex31. This allows us to represent that during the course of the pandemic, 16 COVID deaths occurred in the 10 to 24 age group (R32).
The WHO33 provides statistics on the causes of deaths34 by age groups in the Czech Republic35. Allowing us to represent that the leading causes of deaths in this age group, in CZ, are aneurysm, suicides & car accidents (R36).
Therefore, anyone who isn’t Debunk the Funk37 and has some basic understanding of statistics should understand that we can expect our death rates, in the 10-24 age groups, to be relatively balanced between vaccinated & unvaccinated, unless the claim is out there that COVID vaccines protect you from car accidents & other life hazards. Surprise, this isn’t the case - confirming the dataset is terrible for effectiveness analysis - as anticipated (Perl38, R39).

No doubt that Uncle John Returns40 or another dedicated gas-lighter will try “HVE” - if they haven’t already.
In the meantime, the unpleasant reality which these parties never want to discuss too much persists: you don’t cheat when your product works as advertised, and we already established that they cheated on every metric.
Pfizer/BioNTech C4591001 Trial - Audit Report - v1 (2024-05-31)

This review aims to address significant anomalies and discrepancies that have surfaced from the examination of the data from the Pfizer/BioNTech C4591001 trial, which could have profound implications for public trust and regulatory standards, should they not be adequately and transparently investigated...
As always, and while any persisting error would be my sole fault, thanks to
& for their insights & patients corrections.

http://web.archive.org/web/20240725115146/https://sars2.net/czech.html#Plot_for_ASMR_by_dose_and_date - See the section “Bucket Analysis”
Was present in the article before : “ To calculate the date of birth, he picks a random birth date corresponding to the birth year, for each subject… which is a great way to ensure his code will be impossible to reproduce, and that the population & resulting summaries will change on each iteration of his script.” - but the critic was invalid due to a seed usage - as established by Mongol in the comments.
I had originally wrongly attributed the file origin to Eurostat while, as established by Mongol, it came from CZ’s statistical institute - https://vdb.czso.cz/vdbvo2/faces/en/index.jsf?page=vystup-objekt&z=T&f=TABULKA&skupId=4449&katalog=33517&pvo=SLD21022-VSE&pvo=SLD21022-VSE&str=v335.
https://web.archive.org/web/20240718214004/https://sars2.net/czech.html#ASMR_by_month_and_vaccine_type - Representation of age groups compared to 2021 census and Eurostat
You wrote that on my website I "explained that the following was an ASMR without any reference population being loaded". However in the code you showed, I used the resident population estimates from the 2021 Czech census as my reference population.
I think the word "standard" in a "standard population" means that it's a signpost against which the age-standardized mortality rate is calculated, and not necessarily that it's some established standard that has been defined formally.
In English the word "standard" has multiple meanings, but in other languages the word for a standard population does not have a connotation of a standard in the sense of an ISO standard. For example the Finnish term for ASMR is "ikävakioitu kuolleisuusaste" which literally means something like "age-defaulted mortality degree", and the Finnish term for a standard population is "vakioväestö" which literally means "default population".
And anyway, if I calculate ASMR using a non-standard standard population, what am I supposed to call it if I'm not allowed to call it ASMR?
I asked ChatGPT: "what is a term for a weighted average of age-specific mortality rates where the weight is the number of people that are included in each age group during a reference year like 2020". But it answered: "The term for a weighted average of age-specific mortality rates where the weights are the number of people in each age group during a reference year is known as the Age-Standardized Mortality Rate (ASMR). Age-standardized mortality rates are used to compare mortality rates between populations that have different age structures. This method adjusts for age by applying the age-specific mortality rates of a study population to a standard age distribution. The weights, in this context, are the population numbers in each age group from a reference year (e.g., 2020)."
If you calculate ASMR for the Czech Republic at Mortality Watch, it uses the 2020 Czech population as the standard population by default (which is not any standardized standard): https://www.mortality.watch/explorer/?c=CZE&v=2.
You wrote that you "succeeded in having him admitting his mistake" because I said that I sometimes used a non-standardized standard population to calculate ASMR. But it wasn't any admission of a mistake, because I don't think the standard population for ASMR has to be any standardized standard population like ESP2013.
---
You wrote: "To calculate the date of birth, he picks a random birth date corresponding to the birth year, for each subject… which is a great way to ensure his code will be impossible to reproduce, and that the population & resulting summaries will change on each iteration of his script." However I'm setting a seed in my code before I generate the random birthdays: sars2.net/czech.html#Bucket_analysis.
---
You wrote: "From a second file provided by Eurostats, he picks his reference population - being the 2021 CZ data." In the plot I used the resident population estimates in the 2021 Czech census as my standard population. But I didn't get them from Eurostat but from the website of the Czech Statistical Office: https://vdb.czso.cz/vdbvo2/faces/en/index.jsf?page=vystup-objekt&z=T&f=TABULKA&skupId=4449&katalog=33517&pvo=SLD21022-VSE&pvo=SLD21022-VSE&str=v335.
---
You wrote: "He then employs various hacks & smoothing to make the gum stick". But what hacks did I employ? I just calculated ASMR the regular way, but my plot showed daily data so of course it made sense to display it as a moving average.
On Twitter you wrote: "I hate ASMR and never uses it, my point is that this calculation isn't an ASMR, and will never be an ASMR. Simply not the same math applied, making the chart titles misleading." But when I asked you to explain how my math was different from regular ASMR, you didn't explain it. And I didn't find any place where you explained it in this Substack post either. You just said that I applied "hacks" to calculate ASMR but you didn't explain what the hacks were. But if I'm using the regular formula to calculate ASMR but I simply use a non-standard standard population instead of a standardized standard population, the math should still be the same.
I'm calculating ASMR as a weighted average of age-specific mortality rates, where the weight is the number of people from each age group that is included in the standard population. For example here my standard population was the estimated Czech resident population on January 1st 2020 by single year of age (where ages 100 and above were aggregated together):
> library(data.table)
> t=fread("http://sars2.net/f/czpopdead.csv")
> t=merge(t,t[year==2020,.(std=pop/sum(pop),age)])
> t[,.(asmr=round(sum(dead/pop*std)*1e5)),year][year>=2015]|>print(r=F)
year asmr
2015 1164
2016 1105
2017 1114
2018 1105
2019 1076
2020 1209
2021 1305
2022 1113
---
You pointed out that the record-level data might be missing vaccination records for people who died in case the database record for the vaccination could not be joined with the database record for the death.
That might be the case, but the yearly number of deaths and yearly number of vaccinations in the record-level data are both identical or nearly identical to other sources.
The Czech Statistical Office has published Excel files which show the yearly number of deaths by ICD code, age group, and region: https://csu.gov.cz/produkty/zemreli-podle-seznamu-pricin-smrti-pohlavi-a-veku-v-cr-krajich-a-okresech-fgjmtyk2qr.
I combined the Excel files into a single CSV file here: sars2.net/czech2.html#Deaths_by_ICD_code_region_age_group_and_year.
The yearly number of deaths in the Excel files was identical to yearly number of deaths at Eurostat in 2020-2022. And both were otherwise identical to the record-level data except the record-level data was only missing a single death in 2021:
> rec=fread("curl -Ls github.com/skirsch/Czech/blob/main/data/CR_records.csv.xz|xz -dc")
> reclev=rec[,.(reclev=.N),.(year=year(DatumUmrti))]
> eurostat=fread("http://sars2.net/f/czpopdead.csv")[,.(eurostat=sum(dead)),year]
> icd=fread("http://sars2.net/f/czicd.csv.gz")[,.(icd=sum(dead)),year]
> merge(icd,merge(reclev,eurostat))|>print(r=F)
year icd reclev eurostat
2020 129289 129289 129289
2021 139891 139890 139891
2022 120219 120219 120219
This calculation also shows that in CSV files published by the Czech Ministry of Health, the number of vaccine doses given by up to the end of 2023 is nearly identical to the record-level data: sars2.net/czech2.html#Number_of_vaccine_doses_by_type_in_record_level_data_compared_to_MoH_data.
This PDF describes the national health information system used in the Czech Republic (NZIS) along with the "infectious disease information system" (ISIN) which contains information about COVID cases and vaccines: https://vladci.cz/archive/covid/106/UZIS_2022-02_Struktura_NZIS_106.pdf.
---
You wrote that I aggregated together ages 0-4 even though most deaths in ages 0-4 are in age 0. But that was actually a good point to criticize, and I have switched to treating 0 and 1-4 as separate age groups in some of my newer scripts for the Czech data.
---
You wrote that Eurostat's population estimates for January 1st 2023 were "census data". But I think the population estimates also incorporate other data which was not part of the publication for the 2021 census, so it's not necessarily accurate to call them "census data".
The dataset has resident population estimates on December 31st 2022 by age group, region, and sex: https://data.gov.cz/datová-sada?iri=https%3A%2F%2Fdata.gov.cz%2Fzdroj%2Fdatové-sady%2F00025593%2Fa129a5408e8e5fd99497e9a22c39775e. I now found that the total population size in the dataset is identical to Eurostat's population estimate for January 1st 2023:
> system("wget csu.gov.cz/docs/107508/a53bbc83-5e04-5a74-36f9-549a090a806e/130142-24data051724.zip ;unzip 130142-24data051724.zip")
> pop=fread("130181-23data2022.csv")
> pop[uzemi_typ=="stát"&is.na(vek_txt)&pohlavi_txt=="",hodnota] # region type is whole country, age is empty (all ages), and sex is empty (both males and females)
[1] 10827529
> fread("http://sars2.net/f/czpopdead.csv")[year==2023,sum(pop)]
[1] 10827529
---
You posted a plot which showed that in ages 10-24 unvaccinated people had higher ASMR than vaccinated people. But it might be because of the healthy vaccinee effect, because if for example you look at single years of age in the age range of 10-24, people who died from a suicide or drug overdose were probably less likely to be vaccinated than other people with the same age (but if you compare ages 10-24 as a whole then it's of course biased because people at the upper end of the age group are more likely to die of a suicide but they're also more likely to be vaccinated).
It might be a coincidence, but your plot actually showed that unvaccinated ASMR had a peak around February 2022, which was around the same time when hospitalizations for COVID peaked in ages 0-11, 12-17, and 18-27: http://sars2.net/czech2.html#Hospitalizations_peaked_in_2022_in_the_youngest_age_groups. In ages 80+ my moving average for daily hospitalizations peaked in November 2020, but it peaked in March 2021 in ages 60-79, 40-59, and 20-39, and it only peaked around February 2022 in ages 0-19. So in younger age groups that got vaccinated later, the hospitalizations also peaked later.
However if you look at only unvaccinated people, the hospitalization rate remained high in February 2022 even in the oldest age groups: sars2.net/czech3.html#Hospitalizations_by_age_group_and_vaccination_status.
There's not enough COVID deaths in ages 10-24 to reliably use COVID deaths as the outcome for estimating vaccine efficacy, but there's a lot more hospitalizations than deaths. In the file `nakazeni-hospitalizace-testy.csv` there's 4,686 hospitalizations in ages 0-11, 1,074 in 12-15, 666 in 16-17, and 2,899 in 18-24.
Excellent work and the patience of a saint to trawl through Benjin's AI-based reports.
The fundamental finding from these Kirschian "Motherlode bombshell reports showing the vaccines are killing people (apart from Pfizer which I just said was fine)" is that they are so confounded that the ONLY reason they are released to the public is so that Steve Kirsch can pontificate about them in a way that allows the pharma companies to use his disastrous advertising to show how "safe and effective" their products are whilst the actuaries are incentivised by billions to reinforce that message.
In the meantime the 10-20% excess deaths across most Western countries remain unexplained, because we are not allowed to see raw, auditable data that hasn't been filtered and miscategorised.