


Pfizer/BioNTech C4591001 Trial - Would "de-randomizing" subjects also have been a thing?
Symptoms of frauds are, from far, the most commonly observed ones in this clinical trial.


Introduction
The relative peace of the last Saturday afternoon was interrupted by one of these tweets from
(who is co-writing this article with us), which leaves you no doubt that your schedule of the day will be severely disturbed.
If you haven’t read the thread yet (and you should), let’s just remind that Amyloidosis was comparing the populations screened and randomized between the FA investigators file1 (edited on November 19, 2020), and the Month 6 one2 (edited on March 19, 2021).
He found some upsetting discrepancies as the total count of subjects went “backwards” in some site.
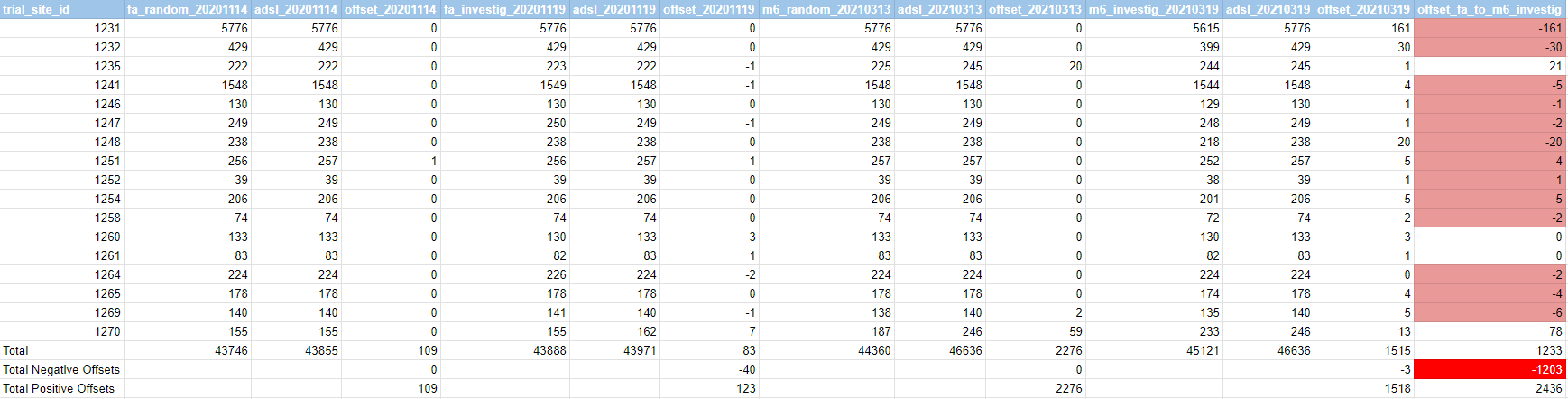
Site 1231, to pick our favorite Argentinian example among many other anomalies, went from 5776 subjects randomized to 5615. Losing 161 randomized subjects in the process.
Which, as often with this trial, isn’t “something supposed to happen”. The process of receiving a randomization number is complex and only occurs after giving written informed consent and passing vital signs, medical history, in- and exclusion criteria checks; it also entails assignment to a trial arm and blood draws3. A randomized trial subject cannot be de-randomized; they can withdraw their consent, the trial can kick them out, they can become lost-to-follow-up, etc. But the fact of their having been part of the trial can’t be deleted. So the two versions of the investigators file showing up different numbers is a bit like pulling two blocks out of the bottom of a jenga tower - the entire construct can no longer be trusted.
The following doesn’t pretend to be an exhaustive review of the issue, but constitutes a “stage of progress” which can be useful to other investigators, along with an highlight of apparent anomalies in subjects who haven’t been randomized.
The R scripts provided assume you have followed the steps indicated in this previous article4.
Discarding rational explanations
Firstly, we quickly eliminated the “rational option” (subjects moving between sites making the total of one lower & the total of another higher), as 63 subjects only changed sites in the ADSL file, parsed by this first script.
These wouldn’t explain the offset of 161 subjects in Argentina - let alone the 1203 subjects lost in randomization between the FA & Month 6 files.
Strangely enough, Pfizer themselves, in April 2021, seem to only be aware of 44 subjects having moved - while no 12-15 years old are included in these 63 subjects.5
We used a second script to download the investigators files, extract all the site ids, screened and randomized subjects - simply confirming the figures already provided in Amyloidosis’s thread. The FA file reports 43 888 subjects randomized, while the M6 file reports 45 1216.
A third script downloads the .PDF files (having them all will have use later, but for now we will use only the randomization files provided). A fourth script extracts all the subjects appearing as “randomized” in the FA7 & M68 randomization files.
The FA file (September 14, 2020) contains 43 746 subjects. The M6 file (March 13, 2021) contains 44 360 subjects. It’s worth noting, here, that 10 subjects are present in the FA randomization file but gone from the M6 one: 10711213, 10891112, 11101123, 11231105, 11331405, 11341006, 11351357, 11491117, 12691070, 12691090.
A fifth script computes the offset, when the November 2020 FA total was higher to the March 2021 Month 6 file. Full results by sites are accessible in this Google Spreadsheet.
The subjects lost between FA & M6 in screening represent a small number, which we can explain by subjects changing site.
Therefore, this problem doesn’t appear to be directly related to the 301 subjects “disappeared”9 (which would also affect the screening), but an entirely separate critical data integrity issue; pointing to the same conclusion: that the trial data has been compromised in the most severe way.
On the other hand, the loss of so many randomized subjects, along with the facts that no file total ever fits the totals reflected by the data, makes little sense, and we spent some time trying to reproduce the totals displayed by the investigator files, trying to relate them to the ADSL data (filtering 12-15 or not, phase 1 subjects, playing on cut-off dates, etc.). In vain so far.
One could object as well that subjects may have been recruited between March 13 and March 19, 2021. But the total of subjects reflected by the ADSL file doesn’t fit anywhere close to this scenario. First the total of subjects in the investigators file (48 092) is already higher than our ADSL total (48 091). Second, the recruitment was already complete long before March 13 (last informed consent and randomization occurred on January 12), both for the 2306 subjects in the 12-15 trial, and the 16+ trial.
In a context where data corruption is, in any case, less a possibility than a certainty, we therefore went to look in the PDF & XPT files, in order to identify if a subject wouldn’t have been screened, recruited, lived his life in the trial, then was suddenly “de-randomized”, returning to the pool of subjects who failed screening or weren’t attributed to a treatment arm.
Looking for de-randomized subjects
We extracted (script) the targeted 1455 “potentially de-randomized” subjects (subjects who have ADSL.ARM on “Not Treated” or “Screen Failure”), from the ADSL file, downloaded & parsed all the PDF files looking for them.
137 subjects are appearing in “c4591001-phase-1-subjects-from-dmw.pdf”10 & 1 appears in the Clinical Study Data Reviewer’s Guide (CSDRG) file11. But these are only a small part of the 1203 subjects disappeared between the “investigators” files.
We then looked for the same 1455 subjects in the XPT files (script).
We generated two views ; one with the total of subjects among these 1455 appearing in a given XPT file (along with the total number of rows), accessible in the following spreadsheet ; and a second file with a view “by subjects”, accessible in the following spreadsheet.
If we represent the count of “total of files in which non-randomized subjects appear”, we obtain the following distribution.

Taking the hypothesis that “996” subjects appearing in 12 .XPT files is the “normal scenario”, and that we wouldn’t investigate the other 459 subjects today, we went looking deeper for the 77 subjects appearing in 20 files or more, reviewing all their entries via yet another script, to review if their history in the trial wouldn’t, by any chance, illustrate a “dirty re-qualification of their treatment arm”, posterior to being actually accepted in the trial.
This would have been a “less dirty” way to exclude a subject from all analysis than plain & simple deletions.
.CSV exports, corresponding to each XPT file and containing only the data about these 77 subjects, have been generated for ease of review (script), and can be accessed on this Google folder, along with a text version of their files appearances. We picked 10 subjects and reviewed their data. Those in which we detected anomalies are described below.
Subject 10131827
Subject 10131827 (text12), a 16 year old boy, got a meningococcal vaccine on Nov. 13 and thus was not randomized on his screening day Dec. 12, yet somehow had blood drawn and a nasal swab taken, which both happen after assessment of non-study vaccines, and withdrew his consent on Jan. 3 2021, from the study he wasn’t randomized in.
Subject 44441622
Subject 44441622 (text13), a 58 years old obese male, was screened on 2020-09-23. At first sight his course in the trial finished this same day, when he failed to pass screening as not eligible for the study at randomization.
He had a COVID illness, with first symptoms on September 21, reported up to October 1st 2020 - 7 days after his screen failure.
This shouldn’t be possible, as data isn’t supposed to be collected on subjects failing to pass screening.
Subject 44441394
Subject 44441394 (text14), a 62 years old male, appears registered as “not assigned” while screened on 2020-09-22.
On September 2, 2020 (20 days before his screening), he had managed to report COVID symptoms, traced in A-D-adc19ef, with “PARAM” values as “PRESENCE OF PROTOCOL DEFINED SYMPTOMS AFTER DOSE”.
Subject 44442149
Subject 44442149 (text15), a 46 years old male, screened on 2020-09-27 and “Not assigned”, also had a COVID visit on the same day. He reported an “insect bite” on October 9, 12 days later, and was “Discontinued because of this AE”.
Subject 10031086
Subject 10031086 (text16), a 73 year old male, was also not assigned after his blood draw “per study sponsor”; however, being a Phase 3 subject, the fact that this could happen is highly irregular. The protocol states that in Phase 3 inclusion/exclusion criteria, blood draw, nasal swab, randomization and injection of assigned study intervention must occur on the same day in that order; he should have been randomized. 10031086 even had a sub-panel of lab tests ordered, proving that this order of progress was not always kept. Also noteworthy is that he was not randomized due to sponsor intervention.
While these subjects are obviously abnormal, it’s worth mentioning that others appear to be legitimate (for example, 10031049 fails Phase 1 screening after tests, due to a Grade 1 abnormality on hematology & blood chemistry tests).
To recapitulate, we have:
1203 subjects disappeared between the investigators files, for which no rational explanation is discernible.
The totals of randomized subjects by sites, which never correspond to the ADSL data, from one document to another.
10 Subjects “de-randomized” between the exported PDF files.
Among a small sample inspected, an high rate has anomalies among subjects which weren’t randomized (yet which is very unlikely to account for the 1203 randomized subjects gone).
Please, leave a comment if you see an explanation we may have overlooked, and happy dives to other researchers.
Page 132, Heading 8.11.2.1 Visit 1 – Vaccination 1: (Day 1)
https://phmpt.org/wp-content/uploads/2022/03/125742_S1_M5_5351_c4591001-interim-mth6-protocol.pdf


 | A guest post by
|
I just want to know when the court cases begin.
The detailed deconstruction of these files has pointed to an astonishing level of corruption. The actual NEJM Dec 2020 Pfizer article already demonstrated major numerical "errors."
It is equally as astonishing that current publications (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10608313/) cite the Pfizer NEJM 2020 article in their systematic review, stating that, "The clinical efficacy was up to 95% in a phase 2 study of mRNA vaccines [11,12]," and spouting the manifest (RRR) nonsense of "clinical efficacy," and thus maintaining THE LIE.
No one will be held to account. A token few may eventually be arrested and tried.
In reality though, much as at the end of WWII and the premature demise of the 1000 year Reich, the current incarnation of manifest evil, the WEF / CEPI / WHO / BMGF / UNEP / UN ECOSOC may simply segue into something else?